
Usando dados para prever mortes no Titanic
O site Kaggle é interessante por vários motivos, o primeiro é que ele simplesmente tenta matar o modelo de consultoria tradicional criando projetos em forma de competições onde o vencedor leva tudo. Essa forma ‘gameficada’ de tratar projetos é ao mesmo tempo genial e perversa, pois em um modelo tradicional uma consultoria seria contratada e pessoas seriam remuneradas pelo seu trabalho (as vezes até demais). No caso do Kaggle, pessoas gastam tempo e recursos em nome da competição, só o melhor resultado é considerado e as pessoas ainda se divertem com isso…Genial!
Outro aspecto interessante é a possibilidade de participar em competições didáticas como por exemplo a do Titanic, onde o objetivo é criar um modelo capaz de prever os sobreviventes de um subgrupo de passageiros.
https://www.kaggle.com/c/titanic
Dentro dessa competição eles nos dão os datasets de treino e teste onde a prática comum é criar um modelo em cima do dataset de treino e utilizar seus parâmetros para tentar prever o que vai acontecer com cada pessoa no dataset de teste. Eles até publicaram um modelo de ‘benchmark’ para o pessoal novo começar a brincar.
https://www.kaggle.com/benhamner/titanic/random-forest-benchmark-r/files
Random Forest
Basicamente o que temos que fazer nessa competição é resolver um problema de classificação onde somente duas respostas são aceitáveis, ‘sobreviveu’ ou ‘não sobreviveu’ e para isso o modelo de benchmark utilizou um método chamado de ‘random forest’
Random Forest são modelos utilizados especificamente para classificações e regressões utilizando-se de várias ‘decision trees’, que é outro método de modelo preditivo.
Bem, pelo menos os nomes são intuitivos, já que uma ‘floresta aleatória’ é um conjunto de múltiplas ‘árvores de decisão’ ou ‘arvores de regressão’ se os valores forem contínuos.
Os dados
Antes de tentar reproduzir o benchmark e tentar fazer nossas melhorias neste modelo, vamos dar passo atrás e tentar entender o que é e como construir uma decision tree e para isso precisamos dos dados.
Os dados estão subdivididos em dois arquivos, o dataset de treino e o de teste, o link abaixo contém os dados e a descrição de cada variável.
https://www.kaggle.com/c/titanic/data
train <- read.csv('.\\ML\\train.csv', stringsAsFactors = F)
test <- read.csv('.\\ML\\train.csv', stringsAsFactors = F)
str(train)
## 'data.frame': 891 obs. of 12 variables:
## $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
## $ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
## $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
## $ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ...
## $ Sex : chr "male" "female" "female" "female" ...
## $ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
## $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
## $ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
## $ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
## $ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
## $ Cabin : chr "" "C85" "" "C123" ...
## $ Embarked : chr "S" "C" "S" "S" ...
str(test) ## 'data.frame': 891 obs. of 12 variables: ## $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ... ## $ Survived : int 0 1 1 1 0 0 0 0 1 1 ... ## $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ... ## $ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ... ## $ Sex : chr "male" "female" "female" "female" ... ## $ Age : num 22 38 26 35 35 NA 54 2 27 14 ... ## $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ... ## $ Parch : int 0 0 0 0 0 0 0 1 2 0 ... ## $ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ... ## $ Fare : num 7.25 71.28 7.92 53.1 8.05 ... ## $ Cabin : chr "" "C85" "" "C123" ... ## $ Embarked : chr "S" "C" "S" "S" ...
É uma base de dados bem legal, 891 observações para criarmos um modelo de treino e 418 para testa-lo, note que esta base já pode ser considerada como sendo ‘tidy’ pois as observações são os IDs dos passageiros e para cada ID temos diversas variáveis que vão desde o nome do indivíduo, quanto ele pagou pela viagem e até onde ele embarcou no navio. Isso não nos deixa muito para fazer em termos de tratamento de dados e já podemos sair modelando direto.
O modelo
Para a criação do modelo vamos usar a biblioteca ‘rpart’.
Para construir o modelo, escrevemos a função basicamente da mesma forma que fazemos em outras funções de modelos lineares onde a fórmula é:
Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked
Em outras palavras, em uma arvore de decisão, queremos saber as probabilidades de um indivíduo bater as botas (Se ele sobreviveu = 1 ; ou não sobreviveu = 0) como uma função ‘~’ (til) das outras variáveis, classe, sexo, idade, etc…Ou seja, a classe em que o indivíduo viaja, seu sexo e idade tem alguma relevância nas suas chances de sobreviver?
Mulheres e crianças primeiro, certo?
library(rpart)
Arvore <- rpart(formula = Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked,
data = train, method = "class")
Vamos dar uma olhada nos resultados desse modelo:
Arvore$variable.importance ## Sex Fare Pclass SibSp Parch Age Embarked ## 124.42633 46.94163 35.11375 17.23859 16.99423 12.45917 11.86495
Esse é o modelo mais simples possível, mas já é possível tirar algumas conclusões interessantes.
A variável mais importante é o Sexo (mulheres, check!) depois disso temos o valor da passagem e a classe que são quase a mesma coisa (mostrando que o modelo pode ser melhorado), depois o tamanho da família do indivíduo (irmãos, esposas, pais e crianças) e por fim a idade…
Vamos mudar um pouco a frase…
Mulheres e ricos primeiro!
Representação visual
O legal mesmo das árvores de decisão é a forma de representar os resultados, existem várias maneiras de se fazer isso, mas a mais fácil é usar a combinação de bibliotecas abaixo e a função fancyRpartPlot, só ajustamos o tamanho da fonte para facilitar a leitura (cex=0.8)
library(rattle) library(rpart.plot) library(RColorBrewer) fancyRpartPlot(Arvore, cex=0.8 )
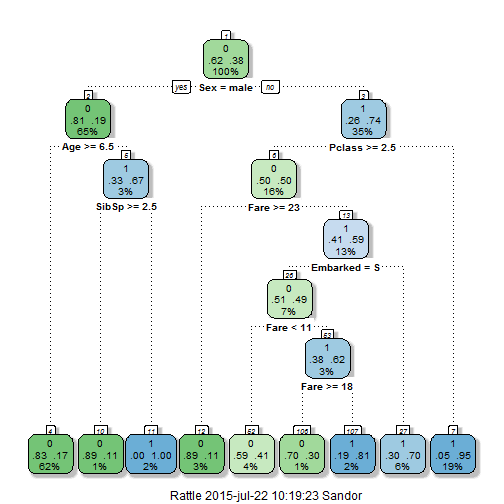
Os resultados
É realmente fácil interpretar os resultados desta árvore. Verde o modelo prevê uma morte lenta nas águas geladas, azul o modelo prevê que o indivíduo irá sobreviver.
A árvore é dividida em níveis sendo que o primeiro dá a probabilidade de sobreviver por simplesmente estar no barco onde a probabilidade é de 62% de não sobreviver, o que é basicamente o número de mortes sobre o total
1 - sum(train$Survived)/length(train$Survived) ## [1] 0.6161616
Depois descemos para o segundo nível onde o sexo do passageiro influencia sua chance de sobreviver, se o passageiro é uma mulher, suas chances de sobreviver sobem para 74%, enquanto que a de um homem é de apenas 19%.
Conforme descemos na árvore aumentamos sua complexidade onde nos extremos, um homem com idade maior que 6 anos tem uma probabilidade de apenas 17% de ter sobrevivido e uma mulher que estivesse viajando na primeira classe tem uma chance de 95% de ter sobrevivido.
Next steps
Este é o modelo mais simples possível e não vai levar ninguém muito longe na competição do Kaggle, já que o modelo de benchmark é uma evolução que usa esse modelo como componente. No próximo post vamos falar um pouco sobre as ‘Random Forests’, explicar um pouco do modelo benchmark, em um futuro próximo tentar criar outros tipos de modelos para tentar enfrentar este problema e, se tudo der certo, subir no ranking da Kaggle…

Pingback: Viés, Variância e Florestas Aleatórias | Dados Dados Dados